699: the modern data stack — with harry glaser
Published 11 months ago • 660 plays • Length 49:28Download video MP4
Download video MP3
Similar videos
-
 0:58
0:58
#shorts version control for data scientists
-
 5:55
5:55
version control for data scientists
-
 2:24
2:24
dbt is great for ml orchestration
-
 1:57:47
1:57:47
h.i. #30: fibonacci dog years
-
 3:13
3:13
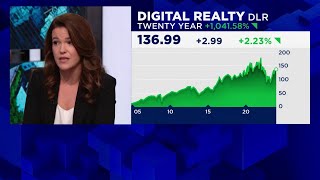
ai will trigger 'hyper-scale demand' of data centers, says morgan stanley's laurel durkay
-
 16:28
16:28
what runs chatgpt? inside microsoft's ai supercomputer | featuring mark russinovich
-
 4:50
4:50
how to run ml models with snowflake and redshift
-
 5:01
5:01
real-time ml monitoring with bi tools (looker, tableau): good or bad idea?
-
 6:15
6:15
three production ml best practices: ci/cd, load balancing and logging
-
 5:06
5:06
664: mit study: chatgpt dramatically increases productivity — with jon krohn (@jonkrohnlearns)
-
 3:58
3:58
the mission of the harvard data science review
-
 6:35
6:35
712: code llama — with jon krohn (@jonkrohnlearns)
-
 11:48
11:48
the four layers of the generative ai stack
-
 7:30
7:30
662: the most popular superdatascience podcast episodes of 2022 — with jon krohn (@jonkrohnlearns)
-
 7:46
7:46
694: catboost: powerful, efficient ml for large tabular datasets — with jon krohn (@jonkrohnlearns)
-
 4:55
4:55
hadley wickham on r vs python
-
 6:34
6:34
israel's a.i. r&d edge
-
 21:02
21:02
resolving the llm user-privacy issue: how to train generative a.i. while keeping data confidential
-
 16:43
16:43
672: open-source "chatgpt": alpaca, vicuña, gpt4all-j, and dolly 2.0 — with @jonkrohnlearns
-
 27:23
27:23
698: how firms can actually adopt a.i. — with rehgan avon
-
 10:59
10:59
748: the five levels of agi — with jon krohn (@jonkrohnlearns)