apache hive - 01 partition an existing data set according to one or more partition keys
Published 8 years ago • 5K plays • Length 17:25Download video MP4
Download video MP3
Similar videos
-
 29:21
29:21
apache hive - 02 partition an existing data set according to one or more partition keys
-
 26:46
26:46
apache hive - create hive partitioned table
-
 14:32
14:32
partitioning
-
 6:22
6:22
creating partitioned tables in hive
-
 1:18
1:18
spark sql - dml and partitioning - introduction to partitioning
-
 14:43
14:43
spark partition | hash partitioner | interview question
-
 8:25
8:25
apache spark partitions introduction
-
 6:56
6:56
unraid parity drive swap procedure 🖥️ how to upgrade parity drive in unraid - increasing parity size
-
 1:57
1:57
advantys configuration download through tcp/ip
-
 7:05
7:05
difference between groupbykey() and reducebykey() in spark rdd api
-
 6:04
6:04
spark partitioning
-
 26:25
26:25
what is rdd in spark? | apache spark rdd tutorial | apache spark training | edureka
-
 10:25
10:25
msck repair for recovering the hive partitions | spark with hive | spark interview questions
-
 3:43
3:43
why should we partition the data in spark?
-
 6:10
6:10
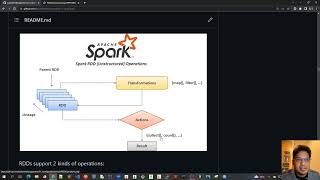
10 - apache spark for java developers - rdd operations
-
 12:11
12:11
spark low level api - rdds
-
 39:00
39:00
storage-partitioned join for apache spark - chao sun, ryan blue
-
 6:46
6:46
spark dataframes and datasets - getting started - creating datasets from rdd
-
 5:09
5:09
23 - create rdd using parallelize method - theory
-
 9:19
9:19
rdds, spark's distributed collection
-
 12:46
12:46
hands-on intro to apache iceberg - 4 - partitioning and call procedures in apache spark