asplos'24 - lightning talks - session 7a - tandem processor: grappling with emerging operators in ne
Published 2 months ago • 57 plays • Length 1:37Download video MP4
Download video MP3
Similar videos
-
 1:29
1:29
asplos'24 - lightning talks - session 7a - feasta: a flexible and efficient accelerator for sparse t
-
 1:26
1:26
asplos'24 - lightning talks - session 7a - cmc: video transformer acceleration via codec assisted ma
-
 1:30
1:30
asplos'24 - lightning talks - session 7a - carat: unlocking value level parallelism for multiplier f
-
 1:30
1:30
asplos'24 - lightning talks - session 10c - optimizing dynamic shape neural networks on accelerators
-
 1:31
1:31
asplos'24 - lightning talks - session 6b - neupims: npu pim heterogeneous acceleration for batched l
-
 1:31
1:31
asplos'24 - lightning talks - session 8c - slimslam: an adaptive runtime for visual inertial simulta
-
 1:27
1:27
asplos'24 - lightning talks - session 7b - siro: empowering version compatibility in intermediate re
-
 1:26
1:26
asplos'24 - lightning talks - session 9d -fermihedral: on the optimal compilation for fermion-to-qub
-
 54:42
54:42
asplos'23 - keynote by bryan catanzaro, nvidia
-
 11:25
11:25
asplos'23 - session 1a - heron: automatically constrained high-performance library generation for de
-
 15:47
15:47
asplos'22 - session 1a - taskstream: accelerating task-parallel workloads by recovering program stru
-
 1:34
1:34
asplos'24 - lightning talks - session 6d - elivagar: efficient quantum circuit search for classifica
-
 1:30
1:30
asplos'24 - lightning talks - session 5b - design of novel analog compute paradigms with ark
-
 1:30
1:30
asplos'24 - lightning talks - session 5a - fast instruction selection for fast digital signal proces
-
 1:19
1:19
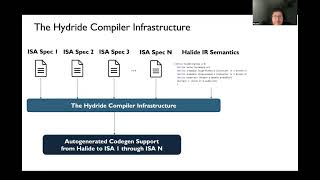
asplos'24 - lightning talks - session 7b - hydride: a retargetable and extensible synthesis based co
-
 1:31
1:31
asplos'24 - lightning talks - session 2b - avoiding instruction centric microarchitectural timing ch
-
 1:20
1:20
asplos'24 - lightning talks - session 2a - what you trace is what you get: dynamic stack layout reco
-
 1:26
1:26
asplos'24 - lightning talks - session 3b - giantsan: efficient memory sanitization with segment fold
-
 1:30
1:30
asplos'24 - lightning talks - session 6d - proximl: building machine learning classifiers for photon
-
 1:36
1:36
asplos'24 - lightning talks - session 8b - metal: caching multi level indexes in domain specific arc
-
 1:22
1:22
asplos'24 - lightning talks - session 4b - codecrunch: improving serverless performance via function