efficient streaming language models with attention sinks (paper explained)
Published 9 months ago • 35K plays • Length 32:27Download video MP4
Download video MP3
Similar videos
-
 33:27
33:27
streamingllm - efficient streaming language models with attention sinks explained
-
 28:26
28:26
retentive network: a successor to transformer for large language models (paper explained)
-
 49:54
49:54
streamingllm: efficient streaming language models with attention sinks (ko / en subtitles)
-
 0:20
0:20
streamingllm demo
-
 4:17
4:17
llm explained | what is llm
-
 6:36
6:36
what is retrieval-augmented generation (rag)?
-
 7:54
7:54
how chatgpt works technically | chatgpt architecture
-
 38:26
38:26
new streamingllm by mit & meta: code explained
-
 5:34
5:34
how large language models work
-
 53:07
53:07
reinforced self-training (rest) for language modeling (paper explained)
-
 0:39
0:39
elon musk laughs at the idea of getting a phd... and explains how to actually be useful!
-
 29:29
29:29
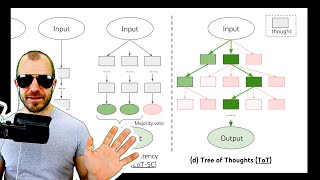
tree of thoughts: deliberate problem solving with large language models (full paper review)
-
 5:46:05
5:46:05
coding a multimodal (vision) language model from scratch in pytorch with full explanation
-
 1:39:32
1:39:32
taskgen overview: open-sourced llm agentic framework - task-based, memory-infused, strictjson
-
 29:56
29:56
an image is worth 16x16 words: transformers for image recognition at scale (paper explained)
-
 1:00
1:00
bert vs gpt