enabling biobank scale genomic processing with spark sql- karen feng (databricks)
Published 4 years ago • 479 plays • Length 31:38Download video MP4
Download video MP3
Similar videos
-
 29:08
29:08
scaling genomics on apache spark by 100x with henry davidge (databricks)
-
 37:38
37:38
introducing glow: an open-source toolkit for large-scale genomic analysis
-
 30:43
30:43
practical genomics with apache spark - tom white
-
 39:17
39:17
accelerating genomics snps processing and interpretation with apache spark
-
 25:17
25:17
migrating a genomics pipeline from bash/hive to spark (azure databricks) – a real world case study
-
 30:48
30:48
building genomic data processing and machine learning workflows using apache spark
-
 1:01:41
1:01:41
genomic variant data ingest and manipulation using glow
-
 1:02:35
1:02:35
from query plan to performance: supercharging your apache spark queries using the spark ui sql tab
-
 33:40
33:40
cd genomics webinar | flaski – a bioinformatics tool for data analysis and visualization
-
 41:19
41:19
an in-depth look into azure synapse spark by daniel coelho
-
 25:41
25:41
improving therapeutic development at biogen with uk biobank data, databricks, and dnanexus
-
 28:01
28:01
building a simd supported vectorized native engine for spark sql
-
 32:41
32:41
spark sql adaptive execution unleashes the power of cluster in large scale with chenzhao guo
-
 27:28
27:28
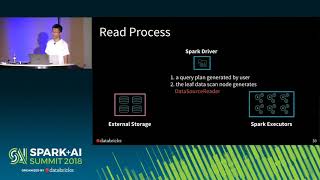
apache spark data source v2 (wenchen fan & gengliang wang)
-
 28:01
28:01
composable data processing with apache spark
-
 21:59
21:59
enabling vectorized engine in apache spark
-
 40:34
40:34
apache spark’s built in file sources in depth gengliang wang (databricks)
-
 29:33
29:33
modular apache spark transform your code in pieces - albert franzi cros alpha
-
 25:22
25:22
analytics zoo - building analytics and ai pipeline for apache spark and bigdl