etl | incremental data load from amazon s3 bucket to amazon redshift using aws glue | datawarehouse
Published 9 months ago • 39K plays • Length 38:28Download video MP4
Download video MP3
Similar videos
-
 37:55
37:55
etl | aws glue | aws s3 | load data from aws s3 to amazon redshift
-
 31:27
31:27
etl | incremental data load from amazon rds mysql to amazon redshift using aws glue | datawarehouse
-
 25:19
25:19
etl | incremental json dataset load from amazon s3 bucket to amazon redshift using aws glue #etljobs
-
 7:35
7:35
how to load s3 data to redshift | create redshift table from csv file in s3
-
 38:16
38:16
etl from aws s3 bucket to amazon redshift using aws glue databrew service
-
 24:05
24:05
etl | amazon redshift | s3 | aws lambda | unload data from amazon redshift to amazon s3 bucket
-
 9:04
9:04
aws glue ingest data from s3 to redshift | etl with aws glue | aws data integration
-
 5:22
5:22
database vs data warehouse vs data lake | what is the difference?
-
 13:11
13:11
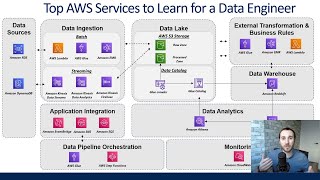
top aws services a data engineer should know
-
 32:33
32:33
amazon redshift for beginners (full course)
-
 1:02:39
1:02:39
use plain english to generate sql code in amazon redshift w/ amazon q developer
-
 27:31
27:31
aws tutorials - incremental data load from jdbc using aws glue jobs
-
 36:59
36:59
etl from amazon rds to amazon redshift with using aws glue service
-
 11:23
11:23
accelerate etl processes for amazon redshift with aws glue | amazon web services
-
 24:09
24:09
etl | aws glue | aws s3 | data cleansing | transforming data with aws glue in etl workflows
-
 35:02
35:02
etl from aws s3 to amazon redshift with aws lambda dynamically.
-
 14:40
14:40
pyspark aws glue etl job to transform and load data from amazon s3 bucket to dynamodb | spark etl