improving sparksql performance by 30%: how we optimize parquet pushdown and parquet reader
Published 3 years ago • 2.9K plays • Length 14:27Download video MP4
Download video MP3
Similar videos
-
 21:25
21:25
how we optimize spark sql jobs with parallel and sync io
-
 36:47
36:47
recent parquet improvements in apache spark
-
 25:47
25:47
sql performance improvements at a glance in apache spark 3.0
-
 7:20
7:20
predicate pushdown for apache parquet in apache spark sql
-
 21:34
21:34
materialized column: an efficient way to optimize queries on nested columns
-
 4:45
4:45
projection and predicate pushdown in apache parquet
-
 14:40
14:40
row format vs column format | why parquet is better than avro | why columnar formats are preferred
-
 41:39
41:39
the columnar roadmap: apache parquet and apache arrow
-
 29:45
29:45
data caching in apache spark | optimizing performance using caching | when and when not to cache
-
 5:16
5:16
an introduction to apache parquet
-
 4:29
4:29
pyspark tutorial : understanding parquet
-
 4:31
4:31
read and write parquet file using apache spark with scala
-
 20:20
20:20
spark performance optimization part1 | how to do performance optimization in spark
-
 34:43
34:43
spark data source v2 performance improvement: aggregate push down
-
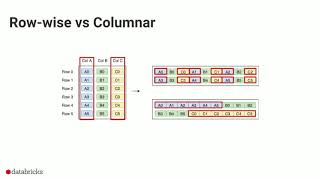 40:46
40:46
the parquet format and performance optimization opportunities boudewijn braams (databricks)
-
 39:07
39:07
optimizing delta parquet data lakes for apache spark - matthew powers (prognos)
-
 15:41
15:41
how to tune and optimize the performance of apache spark data pipelines - dave goodhand
-
 30:35
30:35
bucketing 2.0: improve spark sql performance by removing shuffle
-
 13:03
13:03
optimization in spark
-
 7:41
7:41
parquet vs deltalake - fixing small files syndrom demo
-
 24:38
24:38
data security at scale through spark and parquet encryption