in depth intuition on _$folder$ keys in s3 with hadoop (emr)
Published 2 years ago • 543 plays • Length 10:51Download video MP4
Download video MP3
Similar videos
-
 26:35
26:35
in-depth intuition on the empty success marker file in hadoop , pyspark
-
 15:44
15:44
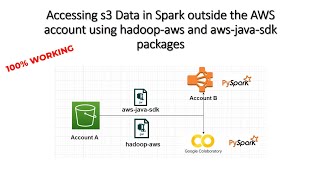
accessing s3 data in spark outside the aws account using hadoop-aws and aws-java-sdk packages
-
 11:05
11:05
emr training: getting started with emr (2 of 11)
-
 6:16
6:16
understand key concepts in amazon s3 in 5 minutes (buckets, objects, keys and regions)
-
 27:18
27:18
aws s3 tutorial for beginners
-
 16:42
16:42
aws emr big data processing with spark and hadoop | python, pyspark, step by step instructions
-
 21:40
21:40
aws iam core concepts you need to know
-
 11:46
11:46
top 50 aws services explained in 10 minutes
-
 38:54
38:54
introduction to aws services
-
 4:44
4:44
what's the difference between s3 prefixes and s3 nested folders?
-
 8:27
8:27
31 - create spark rdd from aws s3 bucket file - unit test code demo 5
-
 14:26
14:26
how to secure access to objects in amazon s3 buckets?
-
 29:08
29:08
view web interfaces hosted on amazon emr clusters
-
 32:01
32:01
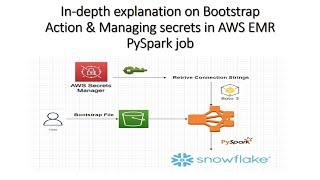
bootstrap action & managing secrets in aws emr pyspark job
-
 22:36
22:36
hadoop on aws using emr tutorial || s3 || athena || glue || quicksight
-
 24:53
24:53
aws athena as data source for apache spark | integration between emr & athena
-
 27:47
27:47
elastic map reduce - hadoop - copying data to s3 for processing
-
 40:58
40:58
aws emr- elastic map reduce & cloud front | aether | session 10
-
 0:20
0:20
what are aws s3 bucket attacks?
-
 16:24
16:24
list files and folders of aws s3 bucket using prefix & delimiter
-
![aws emr tutorial [full course in 60mins]](https://i.ytimg.com/vi/v9nk6mVxJDU/mqdefault.jpg) 1:01:06
1:01:06
aws emr tutorial [full course in 60mins]
-
 9:02
9:02
what is amazon emr and how can i use it for processing data?