meshed-memory transformer for image captioning
Published 4 years ago • 888 plays • Length 1:01Download video MP4
Download video MP3
Similar videos
-
 1:01
1:01
cvpr 2020 - meshed-memory transformer for image captioning
-
 3:54
3:54
boosting vision transformers for image retrieval
-
 16:51
16:51
vision transformer quick guide - theory and code in (almost) 15 min
-
 1:01
1:01
transform and tell: entity-aware news image captioning
-
 1:00
1:00
x-linear attention networks for image captioning
-
 29:56
29:56
an image is worth 16x16 words: transformers for image recognition at scale (paper explained)
-
 9:27
9:27
mist: medical image segmentation transformer with convolutional attention mixing (cam) decoder
-
 4:56
4:56
improve image captioning by estimating the gazing patterns from the caption
-
 4:51
4:51
mm-vit: multi-modal video transformer for compressed video action recognition
-
 1:01
1:01
normalized and geometry-aware self-attention network for image captioning
-
 7:00
7:00
vmformer: end-to-end video matting with transformer
-
 0:30
0:30
image captioning with attention mechanisms
-
 4:50
4:50
fast and interpretable face identification for out-of-distribution data using vision transformers
-
 1:01
1:01
show, edit and tell: a framework for editing image captions
-
 3:42
3:42
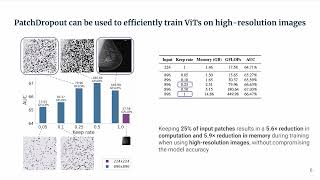
patchdropout: economizing vision transformers using patch dropout
-
 4:51
4:51
resource-efficient hybrid x-formers for vision
-
 11:34
11:34
deep reinforcement learning-based image captioning with embedding reward
-
 0:57
0:57
better captioning with sequence-level exploration