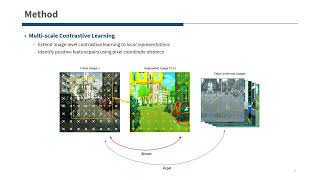
multi-level contrastive learning for self-supervised vision transformers
Published 10 months ago • 73 plays • Length 3:58Download video MP4
Download video MP3
Similar videos
-
 3:58
3:58
multi-view action recognition using contrastive learning
-
 4:01
4:01
multi-scale contrastive learning for complex scene generation
-
 7:59
7:59
contrastive learning for multi-object tracking with transformers
-
 39:13
39:13
dino: emerging properties in self-supervised vision transformers (facebook ai research explained)
-
 4:00
4:00
multimodal vision transformers with forced attention for behavior analysis
-
 5:01
5:01
exploring lightweight hierarchical vision transformers for efficient visual tracking
-
 16:51
16:51
vision transformer quick guide - theory and code in (almost) 15 min
-
 4:43
4:43
patch level representation learning for self supervised vision transformers | cvpr 2022
-
 14:47
14:47
vision transformer for image classification
-
 58:33
58:33
self-supervised learning for computer vision by dr. ym. asano @quva
-
 3:51
3:51
dsformer: a dual-domain self-supervised transformer for accelerated multi-contrast mri reconstructi
-
 0:14
0:14
advancing the state of the art in computer vision with self-supervised vision transformers
-
 6:28
6:28
masking improves contrastive self-supervised learning for convnets, and saliency tells you where
-
 2:35:40
2:35:40
cvpr #18572 - vision transformer: more is different
-
 4:51
4:51
mm-vit: multi-modal video transformer for compressed video action recognition
-
 30:08
30:08
supervised contrastive learning
-
 4:49
4:49
billion-scale pretraining with vision transformers for multi-task visual representations
-
 9:24
9:24
m33d: learning 3d priors using multi-modal masked autoencoders for 2d image and video understanding
-
 1:00
1:00
why transformer over recurrent neural networks