pdf parsing with scanned images, tables, text with docling, claude 3.5, gpt 4, llama 3.2
Published 12 days ago • 542 plays • Length 27:59Download video MP4
Download video MP3
Similar videos
-
 9:35
9:35
llama 2 llm for pdf invoice data extraction
-
 8:35
8:35
classify and parse pdf documents using pdf.co and make
-
 7:21
7:21
build an ai app to extract pdf data
-
 19:05
19:05
marker:get your pdfs ready for rag & llms|high accuracy open-source tool #ai #llm #pdf #generativeai
-
 13:15
13:15
extract pdf content with python
-
 17:00
17:00
extract text, links, images, tables from pdf with python | pymupdf, pypdf, pdfplumber tutorial
-
 29:58
29:58
chunk large complex pdfs to summarize using llm
-
 21:33
21:33
python rag tutorial (with local llms): ai for your pdfs
-
 8:06
8:06
best way to extract tables from pdf with llms
-
![fully local mistral ai pdf processing [hands-on tutorial]](https://i.ytimg.com/vi/wZDVgy_14PE/mqdefault.jpg) 12:51
12:51
fully local mistral ai pdf processing [hands-on tutorial]
-
 34:24
34:24
unstract - how to extract data from pdfs using llms
-
 14:12
14:12
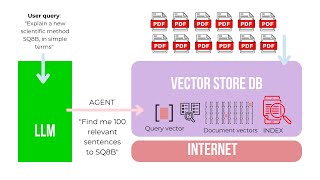
q: how put 1000 pdfs into my llm?
-
 9:52
9:52
ingest pdfs at scale for rag with llmware
-
 0:19
0:19
how to edit pdf
-
 22:27
22:27
master pdf chat with langchain - your essential guide to queries on documents
-
 0:19
0:19
how to type & write on any pdf ✏️
-
 15:39
15:39
extract tables texts from .htm pages for rag using llama-index & unstructured
-
 8:21
8:21
extract tables from pdfs