petabyte-scale lakehouses with dbt and apache hudi
Published Streamed 1 year ago • 882 plays • Length 28:24Download video MP4
Download video MP3
Similar videos
-
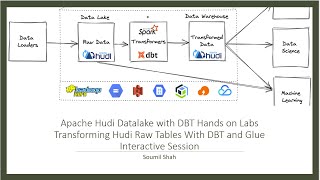 14:35
14:35
apache hudi with dbt hands on lab.transform raw hudi tables with dbt and glue interactive session
-
 29:28
29:28
data alchemy: transforming raw data to gold with apache hudi and dbt
-
 57:56
57:56
ep22 - dremio and data lakehouse table formats (apache iceberg, delta lake and apache hudi & dremio)
-
 30:06
30:06
a hudi live event: incremental data processing with spark & dbt
-
 33:08
33:08
prestodb and apache hudi for the lakehouse - sagar sumit & bhavani sudha saktheeswaran
-
 1:00:42
1:00:42
building an open data lakehouse on aws with presto and apache hudi
-
 31:20
31:20
subsurface 2020: running apache iceberg at petabyte scale - takeaways & lessons learned
-
 22:19
22:19
spark etl with lakehouse | apache hudi
-
 49:54
49:54
building a large-scale transactional data lake using apache hudi
-
 30:54
30:54
building large scale, transactional data lakes with apache hudi - nishith agarwal
-
 9:25
9:25
introduction to the open data lakehouse, including what is presto and what is apache hudi
-
 11:03
11:03
apache hudi, spark, dbt, glue hive metastore setup | locally | in minutes – hands-on exercise!
-
 47:06
47:06
building an open data lake house using trino and apache iceberg
-
 2:06
2:06
compare apache iceberg, apache hudi, and delta lake table partitioning formats for data lakes
-
 7:21
7:21
great article|apache hudi vs delta lake vs apache iceberg - lakehouse feature comparison by onehouse
-
 30:03
30:03
rewriting history: migrating petabytes of data to apache iceberg using trino