revisiting the exploration-exploitation trade-off in bandit models
Published 8 years ago • 1.5K plays • Length 31:40Download video MP4
Download video MP3
Similar videos
-
 39:07
39:07
bandits and agents: how to incentivize exploration?
-
 54:29
54:29
the contextual bandits problem
-
 47:31
47:31
learning across bandits in high dimension via robust statistics
-
 26:58
26:58
on the complexity of best arm identification in multi-armed bandit models
-
 11:49
11:49
efficient pure exploration for combinatorial bandits with semi-bandit feedback
-
 47:35
47:35
adaptivity and confounding in multi-armed bandit experiments
-
 48:36
48:36
incentivized exploration
-
![bandit [complete] | overthewire](https://i.ytimg.com/vi/lO3u46UHYUg/mqdefault.jpg) 4:26:26
4:26:26
bandit [complete] | overthewire
-
 12:56
12:56
epsilon greedy in rl
-
 32:42
32:42
original d&d solo actual play - session 75; the rangers - quest for sword and shield- part 2
-
 46:00
46:00
dynamic regret minimization for bandits without prior knowledge
-
 5:07
5:07
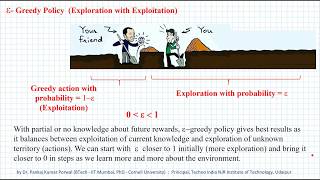
exploration exploitation dilemma greedy policy and epsilon greedy policy - reinforcement learning
-
 52:30
52:30
exploration and exploitation in structured stochastic bandits part 1
-
 2:02
2:02
speed-vs-accuracy tradeoff in collective estimation: an adaptive exploration-exploitation case
-
 44:17
44:17
bandit learning under differential privacy