scaling rag and embedding computations with ray and pinecone
Published 4 months ago • 177 plays • Length 29:05Download video MP4
Download video MP3
Similar videos
-
 4:23
4:23
vector databases simply explained! (embeddings & indexes)
-
 51:43
51:43
build retrieval-augmented generation (rag) with databricks and pinecone
-
 28:39
28:39
scaling ai applications with databricks, huggingface and pinecone
-
 18:41
18:41
openai embeddings and vector databases crash course
-
 6:36
6:36
what is retrieval-augmented generation (rag)?
-
 1:01:17
1:01:17
making, moving, and managing millions of embeddings
-
 1:36:49
1:36:49
rag fundamentals and advanced techniques – full course
-
 29:04
29:04
rag, semantic search, embedding, vector... find out what the terms used with generative ai mean!
-
 15:32
15:32
rag from the ground up with python and ollama
-
 0:55
0:55
vector databases (pinecone)
-
 0:58
0:58
comparing rag approaches: langchain/pinecone, llamaindex, and groundx
-
 15:09
15:09
fullstack vectors with pinecone
-
 8:29
8:29
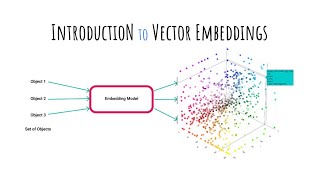
a beginner's guide to vector embeddings
-
 18:35
18:35
building production-ready rag applications: jerry liu
-
 20:34
20:34
practical rag - choosing the right embedding model, chunking strategy, and more
-
 2:33:11
2:33:11
learn rag from scratch – python ai tutorial from a langchain engineer
-
 14:02
14:02
chunking strategies in rag: optimising data for advanced ai responses
-
 16:19
16:19
understanding embeddings in rag and how to use them - llama-index