usenix atc '23 - vectorvisor: a binary translation scheme for throughput-oriented gpu acceleration
Published 1 year ago • 527 plays • Length 25:10Download video MP4
Download video MP3
Similar videos
-
 22:47
22:47
usenix atc '20 - scaph: scalable gpu-accelerated graph processing with value-driven differential...
-
 19:23
19:23
usenix atc '23 - farreach: write-back caching in programmable switches
-
 17:14
17:14
usenix atc '23 - towards iterative relational algebra on the gpu
-
 17:14
17:14
usenix atc '22 - faith: an efficient framework for transformer verification on gpus
-
 20:30
20:30
usenix atc '24 - power-aware deep learning model serving with μ-serve
-
 19:52
19:52
usenix atc '23 - confidential computing within an ai accelerator
-
 23:26
23:26
usenix atc '23 - sage: software-based attestation for gpu execution
-
 16:39
16:39
usenix atc '22 - serving heterogeneous machine learning models on multi-gpu servers...
-
 31:06
31:06
compute innovation with cisco ucs x-series
-
 1:02:59
1:02:59
$amd advanced micro devices q3 2024 earnings conference call
-
 5:37
5:37
the latest chip for always-on sound & vision ai | syntiant at ew 2024
-
 21:47
21:47
usenix atc '23 - beware of fragmentation: scheduling gpu-sharing workloads with fragmentation...
-
 19:55
19:55
usenix atc '24 - metis: fast automatic distributed training on heterogeneous gpus
-
 20:54
20:54
usenix atc '22 - whale: efficient giant model training over heterogeneous gpus
-
 20:02
20:02
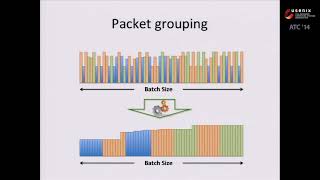
usenix atc '14 - gaspp: a gpu-accelerated stateful packet processing framework
-
 19:12
19:12
usenix atc '23 - sponge: fast reactive scaling for stream processing with serverless frameworks
-
 18:26
18:26
usenix atc '23 - tc-gnn: bridging sparse gnn computation and dense tensor cores on gpus
-
 20:06
20:06
usenix atc '23 - legion: automatically pushing the envelope of multi-gpu system for billion-scale...
-
 20:50
20:50
usenix atc '23 - envpipe: performance-preserving dnn training framework for saving energy
-
 1:28
1:28
amd epyc 7003 series processors and xilinx alveo accelerator cards
-
 15:56
15:56
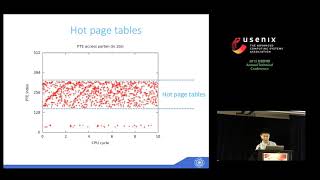
usenix atc '15 - boosting gpu virtualization performance with hybrid shadow page tables
-
 15:41
15:41
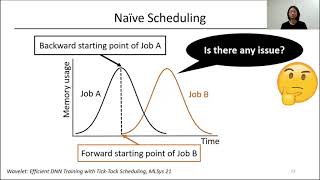
usenix atc '21 - zico: efficient gpu memory sharing for concurrent dnn training