when vision transformers outperform resnets without pretraining | paper explained
Published 3 years ago • 4.5K plays • Length 23:14Download video MP4
Download video MP3
Similar videos
-
 34:51
34:51
do vision transformers see like convolutional neural networks? | paper explained
-
 31:54
31:54
dino: emerging properties in self-supervised vision transformers | paper explained!
-
 24:57
24:57
vision transformer (vit) - an image is worth 16x16 words | paper explained
-
 30:49
30:49
vision transformer basics
-
 13:09
13:09
vision transformer (vit) 用于图片分类
-
 16:44
16:44
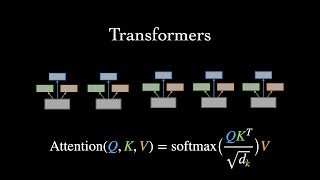
what are transformer neural networks?
-
 1:11:31
1:11:31
vit论文逐段精读【论文精读】
-
 21:00
21:00
convnet beats vision transformers (convnext) paper explained
-
 15:22
15:22
fastformer: additive attention can be all you need | paper explained
-
 45:55
45:55
non-parametric transformers | paper explained
-
 22:39
22:39
focal transformer: focal self-attention for local-global interactions in vision transformers
-
 16:51
16:51
vision transformer quick guide - theory and code in (almost) 15 min
-
 11:10
11:10
swin transformer paper animated and explained
-
 0:14
0:14
advancing the state of the art in computer vision with self-supervised vision transformers
-
 4:02
4:02
scaling vision transformers: revealing the power of large models