data engineering made easy: build datalake on s3 with apache hudi & glue hands-on labs for beginners
Published 1 year ago • 10K plays • Length 41:42Download video MP4
Download video MP3
Similar videos
-
 8:18
8:18
easy step by step guide for beginner ingest csv files into hudi with aws glue | hands on labs
-
 10:10
10:10
how to convert existing data in s3 into apache hudi transaction datalake with glue | hands on lab
-
 9:47
9:47
create your hudi transaction datalake on s3 with emr serverless for beginners in fun and easy way
-
 16:15
16:15
getting started with kafka and glue to build real time apache hudi transaction datalake
-
 3:06
3:06
learn how to use aws glue crawler with hudi tables to catlog the data
-
 7:25
7:25
efficient data ingestion with glue concurrency and hudi data lake
-
 5:54
5:54
how to use apache hudi with aws glue studio visual editor | hands on lab
-
 6:08
6:08
getting started with apache hudi with pyspark and aws glue #1 intro
-
 7:21
7:21
how to use sparksql to create hudi tables on aws glue | hands on
-
 10:47
10:47
insert | update | delete on datalake (s3) with apache hudi and glue pyspark
-
 11:45
11:45
step by step guide how to move data with cdc from datalake s3 to aws aurora postgres using glue
-
 18:47
18:47
learn schema evolution in apache hudi transaction datalake with hands on labs
-
 5:59
5:59
simple 5 steps guide to get started with apache hudi and glue 4.0 and query the data using athena
-
 13:58
13:58
getting started with apache hudi with pyspark and aws glue #2 hands on lab with code
-
 44:50
44:50
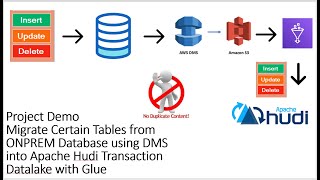
step by step guide on migrate certain tables from db using dms into apache hudi transaction datalake
-
 11:34
11:34
writing data quality and validation scrips for hudi datalake with glue and pydeequ| hands on lab
-
 10:42
10:42
migrate certain tables from onprem db using dms into apache hudi transaction datalake with glue|demo