getting started with kafka and glue to build real time apache hudi transaction datalake
Published 1 year ago • 2.5K plays • Length 16:15Download video MP4
Download video MP3
Similar videos
-
 10:10
10:10
how to convert existing data in s3 into apache hudi transaction datalake with glue | hands on lab
-
 6:53
6:53
lets build streaming solution using kafka pyspark and apache hudi hands on lab with code
-
 5:59
5:59
simple 5 steps guide to get started with apache hudi and glue 4.0 and query the data using athena
-
 6:08
6:08
getting started with apache hudi with pyspark and aws glue #1 intro
-
 41:42
41:42
data engineering made easy: build datalake on s3 with apache hudi & glue hands-on labs for beginners
-
 8:21
8:21
how do i ingest extremely small files into hudi data lake with glue incremental data processing
-
 3:06
3:06
learn how to use aws glue crawler with hudi tables to catlog the data
-
 6:55
6:55
learn how to use apache flink with kafka & build transactional datalakes on s3 using pyflink locally
-
 18:37
18:37
build a spark pipeline to analyze streaming data using aws glue, apache hudi, s3 and athena
-
 9:47
9:47
create your hudi transaction datalake on s3 with emr serverless for beginners in fun and easy way
-
 17:06
17:06
bring data from source using debezium with cdc into kafka&s3sink &build hudi datalake | hands on lab
-
 11:52
11:52
introduction to apache hudi for data lake management! apache hudi for beginners!
-
 5:54
5:54
how to use apache hudi with aws glue studio visual editor | hands on lab
-
 7:21
7:21
how to use sparksql to create hudi tables on aws glue | hands on
-
 18:47
18:47
learn schema evolution in apache hudi transaction datalake with hands on labs
-
 5:36
5:36
rfc-51 change data capture in apache hudi like debezium and aws dms hands on labs
-
 14:35
14:35
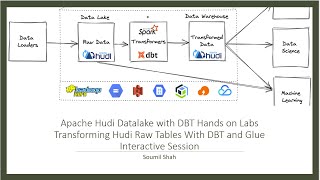
apache hudi with dbt hands on lab.transform raw hudi tables with dbt and glue interactive session
-
 13:58
13:58
getting started with apache hudi with pyspark and aws glue #2 hands on lab with code