deploy a model with #nvidia #triton inference server, #azurevm and #onnxruntime.
Published 2 years ago • 5.7K plays • Length 5:09Download video MP4
Download video MP3
Similar videos
-
 2:43
2:43
getting started with nvidia triton inference server
-
 24:40
24:40
deploying an object detection model with nvidia triton inference server
-
 2:46
2:46
how to deploy huggingface’s stable diffusion pipeline with triton inference server
-
 11:02
11:02
deploy transformer models in the browser with #onnxruntime
-
 5:48
5:48
deploy ml models with azure functions and onnx runtime
-
 2:46
2:46
production deep learning inference with nvidia triton inference server
-
 1:58
1:58
elon musk fires employees in twitter meeting dub
-
 16:13
16:13
lightning talk: triton compiler - thomas raoux, openai
-
 12:11
12:11
the triton language | philippe tillet
-
 24:40
24:40
deploying an object detection model with nvidia triton inference server
-
 32:27
32:27
nvidia triton inference server and its use in netflix's model scoring service
-
 1:07:45
1:07:45
optimizing real-time ml inference with nvidia triton inference server | datahour by sharmili
-
 20:15
20:15
onnx runtime azure ep for hybrid inferencing on edge and cloud
-
 37:11
37:11
azure cognitive service deployment: ai inference with nvidia triton server | brkfp04
-
 44:35
44:35
onnx and onnx runtime
-
 3:24
3:24
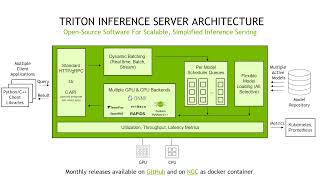
triton inference server architecture
-
 24:40
24:40
deploying an object detection model with nvidia triton inference server
-
 11:39
11:39
optimizing model deployments with triton model analyzer
-
 24:40
24:40
deploying an object detection model with nvidia triton inference server
-
 10:03
10:03
011 onnx 20211021 salehi onnx runtime and triton
-
 1:23
1:23
nvidia triton inference server: generative chemical structures