podcast: optimizing data lake performance with apache hudi compaction: strategies and benefits
Published 1 year ago • 202 plays • Length 1:47Download video MP4
Download video MP3
Similar videos
-
 7:25
7:25
efficient data ingestion with glue concurrency and hudi data lake
-
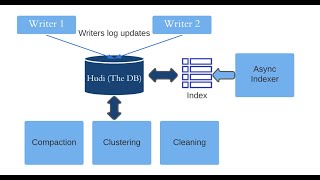 5:07
5:07
efficient data lake management with apache hudi cleaner: benefits of scheduling data cleaning #1
-
 8:48
8:48
efficient data lake management with apache hudi cleaner: benefits of scheduling data cleaning #2
-
 41:42
41:42
data engineering made easy: build datalake on s3 with apache hudi & glue hands-on labs for beginners
-
 58:05
58:05
streaming data ingestion into apache iceberg
-
 17:06
17:06
bring data from source using debezium with cdc into kafka&s3sink &build hudi datalake | hands on lab
-
 45:50
45:50
why apache hudi apache doris is an ace for data lake analytics
-
 2:36
2:36
podcast 3 : benefits of using a transactional data lake and how apache hudi can help
-
 43:10
43:10
build a fast data lake analysis solution with apache hudi and apache doris
-
 1:38
1:38
podcast: maximizing efficiency with merge on read table type in apache hudi: benefits and use cases
-
 0:52
0:52
#3 unlock the true potential of your data with apache hudi
-
 10:38
10:38
building a universal data lakehouse with apache xtable, minio, and trino (hudi | iceberg| delta)
-
 2:25
2:25
podcast: maximizing data management efficiency with apache hudi's clustering feature
-
 49:35
49:35
apache hudi : the data lake platform - vinoth chandar
-
 6:08
6:08
getting started with apache hudi with pyspark and aws glue #1 intro
-
 7:05
7:05
mastering file sizing in hudi: boosting performance and efficiency
-
 8:29
8:29
build real time streaming pipeline with apache hudi kinesis and flink | hands on lab
-
 0:31
0:31
the ultimate guide to data engineering and data lake in 2021
-
 0:28
0:28
optimizing data storage with hudi's mor table type