testing framework giskard for llm and rag evaluation (bias, hallucination, and more)
Published 8 months ago • 6.1K plays • Length 40:35Download video MP4
Download video MP3
Similar videos
-
 0:51
0:51
how rag solves hallucinations with llm's #ai #llm #gpt
-
 1:00:40
1:00:40
mitigating llm hallucinations with a metrics-first evaluation framework
-
 7:23
7:23
ep 6. conquer llm hallucinations with an evaluation framework
-
 0:53
0:53
what is rag?
-
 6:36
6:36
what is retrieval-augmented generation (rag)?
-
 9:38
9:38
why large language models hallucinate
-
 12:05
12:05
testing llms with giskard and mlops best practices
-
 50:42
50:42
how to evaluate an llm-powered rag application automatically.
-
 21:11
21:11
check hallucination of llms and rags using open source evaluation model by vectara
-
 9:41
9:41
what is retrieval augmented generation (rag) - augmenting llms with a memory
-
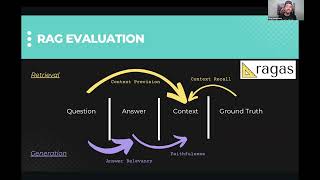 37:21
37:21
session 7: rag evaluation with ragas and how to improve retrieval
-
 3:49
3:49
ai explained - ai llm retrieval-augmented generation (rag)
-
 1:02:56
1:02:56
llm hallucinations in rag qa - thomas stadelmann, deepset.ai
-
 8:03
8:03
rag explained
-
 44:22
44:22
rag time! evaluate rag with llm evals and benchmarking
-
 18:39
18:39
abigail haddad - automating tests for your rag chatbot or other generative tool