l19.4.1 using attention without the rnn -- a basic form of self-attention
Published 3 years ago • 12K plays • Length 16:11Download video MP4
Download video MP3
Similar videos
-
 16:09
16:09
l19.4.2 self-attention and scaled dot-product attention
-
 22:19
22:19
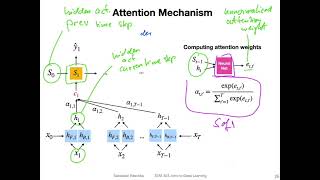
l19.3 rnns with an attention mechanism
-
 7:37
7:37
l19.4.3 multi-head attention
-
 0:18
0:18
transformers | basics of transformers
-
 5:34
5:34
attention mechanism: overview
-
 4:30
4:30
attention mechanism in a nutshell
-
 4:44
4:44
self-attention in deep learning (transformers) - part 1
-
 22:36
22:36
l19.5.1 the transformer architecture
-
 1:00
1:00
why transformer over recurrent neural networks
-
 15:02
15:02
self attention in transformer neural networks (with code!)
-
 24:51
24:51
attention for rnn seq2seq models (1.25x speed recommended)
-
 0:33
0:33
what is mutli-head attention in transformer neural networks?
-
 0:51
0:51
why sine & cosine for transformer neural networks
-
 9:11
9:11
transformers, explained: understand the model behind gpt, bert, and t5
-
 14:32
14:32
rasa algorithm whiteboard - transformers & attention 1: self attention
-
 1:00
1:00
5 concepts in transformers (part 3)
-
 0:54
0:54
different masks in the transformer
-
 0:46
0:46
multi head architecture of transformer neural network
-
 1:00
1:00
bert vs gpt